


项目简介
本项目使用K-Means聚类改进传统的基于内容相似度的推荐算法,实现简单的新闻推荐。
0. 项目依赖
import pandas as pd
import jieba
import math
from collections import Counter
import numpy as np
import sys
from sklearn.cluster import KMeans
1. 读取数据
定义函数读取new.xlsx文件中的新闻IDnew_id, 新闻标题new_title, 新闻内容new_content,分别存入变量news_id,titles,contents中。
def load_data(file_path):
news = pd.read_excel(file_path)
news_id = news['new_id'].values.tolist()
titles = news['new_title'].values.tolist()
contents = news['new_content'].values.tolist()
return news_id, titles, contents
2. 处理数据
定义分词函数split_word,实现后续对contents去停用词、jieba分词的操作,建立新闻内容语料库。
def split_word(lines):
with open("stopwords.txt", encoding="utf-8") as f:
stopwords = f.read().split("\n")
words_list = []
for line in lines:
words = [word for word in jieba.cut(line.strip().replace("\n", "").replace("\r", "").replace("\ue40c", "")) if word not in stopwords]
words_list.append(" ".join(words))
return words_list
3. 计算TF-IDF
定义tfidf_compute函数,计算新闻内容语料库中所有新闻的TF-IDF值。
统计语料库中每条新闻包含词语对应的词频sen_word_dics。
-
TF-IDF的计算公式为:
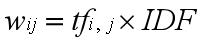
-
其中,可以通过计算词语在文本中出现的次数与文本d中总词语数量的比值得到:
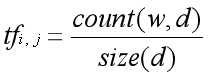
-
IDF值由总文本数量除以出现过词语的其他文本数量得到的比值的对数计算得到,即:
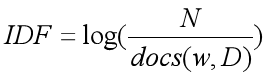
- 首先,计算每个词语对应的IDF值:
idf_dic。- 其次,按词语在语料库中出现的次数对词语进行排序。
- 再次,对每条新闻内容计算包含词语的TF值:
tf_dic,与IDF值相乘即为对应词语的TF-IDF值:tfidf_dic。- 最后,对全部特征词建立索引,并建立新闻和特征词的TF-IDF矩阵。
def tfidf_compute(corpus, max_words):
sen_word_dics = [Counter(line.split()) for line in corpus]
# compute IDF
total = len(sen_word_dics)
idf_dic = {}
for sen_word_dic in sen_word_dics:
for word, value in sen_word_dic.items():
if value > 0:
idf_dic[word] = idf_dic.setdefault(word, 0) + 1
idf_dic = {item[0]: (lambda item: math.log(total / item[1] + 1))(item) for item in
idf_dic.items()} # 计算IDF值
corpus_word_dic = Counter((" ".join(corpus)).split())
corpus_word_tuples = sorted(corpus_word_dic.items(), key=lambda x: x[1], reverse=True) # 按整个语料库中的词频对词语排序
corpus_word_tuples = corpus_word_tuples[:max_words] # 仅使用前max_words个词语作为特征词
cur_features = corpus_word_tuples
tfidf_dics = []
for sen_word_dic in sen_word_dics:
word_total = sum(sen_word_dic.values())
tf_dic = {item[0]: (lambda item: item[1] / word_total)(item) for item in sen_word_dic.items()} # 计算TF值
try:
tfidf_dic = {item[0]: (lambda item: item[1] * idf_dic[item[0]])(item) for item in
tf_dic.items()} # 计算每条新闻中词语的TFIDF值
except AttributeError as e:
print(e, file=sys.stderr)
print("Maybe you should: call TFIDF.fit() function first.", file=sys.stderr)
exit(1)
tfidf_dics.append(tfidf_dic)
index_dic = {idx: item[0] for idx, item in enumerate(cur_features)} # 将每个特征词对应到索引上
X = np.zeros((len(tfidf_dics), len(index_dic)))
for i, tfidf_dic in enumerate(tfidf_dics):
for j, word in index_dic.items():
X[i, j] = tfidf_dic.setdefault(word, 0)
return X
4. K-Means聚类
定义K-Means聚类函数kmeans_comput,并建立类簇标签的索引。
def kmeans_comput(item_array):
kmeans = KMeans(n_clusters=3, random_state=0).fit(item_array)
index2label = {idx: label for idx, label in enumerate(kmeans.labels_)} #
label2index = {}
for idx, label in index2label.items():
label2index.setdefault(label, []).append(idx)
return index2label, label2index
5. 相似度计算
定义余弦相似度cosine_similarity计算新闻内容之间的相似度矩阵。
def cosine_similarity(matrix):
sim_matrix = np.zeros((len(matrix), len(matrix)))
for i in range(len(matrix)):
for j in range(len(matrix)):
sim_matrix[i, j] = np.dot(matrix[i], matrix[j]) / ((10e-20 + np.linalg.norm(matrix[i])) * (10e-20 + np.linalg.norm(matrix[j])))
return sim_matrix
6. 实现新闻推荐
改进的新闻推荐算法步骤如下:
- 调用
load_data函数读取数据。 - 调用
split_word函数对新闻内容contents去停用词、分词。 - 调用
tfidf_compute函数计算每条新闻特征词的TF-IDF值对新闻进行向量化表示,此处使用每条新闻中词频最高的前2000个词作为特征词,建立1058*2000的新闻*特征词矩阵。 - 调用
kmeans_comput函数对上一步得到的新闻内容特征向量进行K-Means聚类。 - 对每个类簇内的新闻,调用
cosine_similarity函数计算余弦相似度实现Top5相似新闻推荐。
if __name__ == "__main__":
recommend_num = 5
news_ids, titles, contents = load_data('new.xlsx')
content_words = split_word(contents)
tfidf = tfidf_compute(content_words, max_words=2000)
index2label, label2index = kmeans_comput(tfidf)
recommend_dict = {}
for label, indexs in label2index.items():
sub_tfidf = tfidf[indexs]
sim_matrix = cosine_similarity(sub_tfidf)
indices = np.argsort(sim_matrix, axis=1)[:, ::-1][:, 1:recommend_num+1].tolist()
similarities = np.sort(sim_matrix, axis=1)[:, ::-1][:, 1:recommend_num+1].tolist()
for i, index in enumerate(indexs):
recommend_dict[index] = [(news_ids[indexs[idx]], titles[indexs[idx]], similarities[i][j]) for j, idx in enumerate(indices[i])]
recommend_result = {news_ids[idx]: recommend_dict[idx] for idx in recommend_dict}
# 推荐结果
for i, (news_id, recommend_list) in enumerate(recommend_result.items()):
print("推荐给新闻《{}》的新闻:".format(titles[news_ids.index(news_id)]))
for _, title, similarity in recommend_list:
print("\t\t《{}》:{:.5}".format(title, similarity))
print()
7. 推荐结果展示
与目标新闻最为相似的5条新闻和他们之间的相似度如图所示:



评论区