


1 基础模型介绍
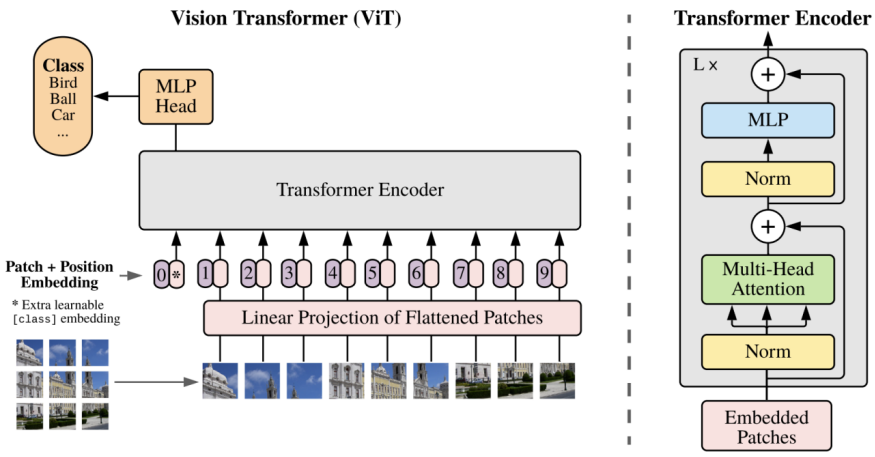
1.1 ViT
ViT (Vision Transformer) 模型结合了CV和NLP领域的知识,它首先将原始图像分割为固定大小的若干块,并对每个图像块进行线性嵌入将其扁平化为一个序列,然后把得到的向量序列输入到原始Transformer模型的编码器中,最后连接到全连接层,对图片进行分类。
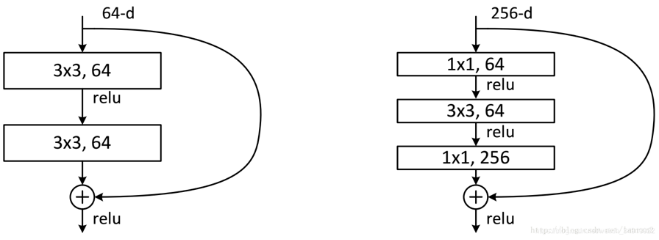
1.2 Resnet
ResNet (Residual Neural Network) 是CV领域的一个经典模型,它有5种常用的模型结构,即Resnet18、Resnet34、Resnet50、Resnet101和Resnet152。其中,Resnet18和Resnet34采用的残差块是BasicBlock结构,如左图所示。Resnet50、Resnet101和Resnet152采用的残差块是一个Bottleneck结构,如右图所示。
2 两个改进方向
2.1 ResPViT
- 利用ViT对像素的关注机制来处理和分类图像。
ResPViT是基于Resnet模型对图像语义的理解而建立的像素特征信息融合的模型。与ViT的模型结构不同,ResPViT在原ViT的每个编码器层之前增加了一个残差块,每个图像块不再是一个子图像,而是图像中的一个个像素。每个ViT编码器层的输出将被重塑为前一个残差块的输出形状,作为下一个残差块的输入。

2.2 ResCViT
- 利用ViT对通道的关注机制来处理和分类图像。
ResCViT 融合了图像特征图中通道间的信息。ResCViT模型在ViT模型之前增加了两个不同的残差块,该模块的输出是一个 H×W×C 的特征图。我们将特征图中每个通道的特征作为一个图像块,即ViT中图像块的数量为 C ,每个图像块的维数为 H×W 。

3 看看实验效果
- Dataset: Cifar10
- Baseline: Resnet18, Resnet50, ViT
| Method | Accuracy |
|---|---|
| Resnet18 | 0.96034 |
| Resnet50 | 0.88970 |
| ViT | 0.33614 |
| ResPViT-18 | 0.25276 |
| ResPViT-50 | 0.12716 |
| ResCViT-BasicBlock | 0.41472 |
| ResCViT-Bottleneck | 0.43656 |
4 总结
ResPViTT模型融合像素特征信息并不能帮助ViT更好地处理图像数据,且使得分类效果变得更差。ResCViT模型方案一定程度上提高了原始ViT模型的分类效果,且还有能进一步提升的空间。
5 项目地址和描述
Enhanced-VIT
main.py
/models/model.py
/models/rest.py
/models/resvit.py
/models/vit.py


评论区