


YOLOX 源码解析
最近用 yolox 的发现了一个很神奇的现象,简而言之 yolox-tiny 在单目标检测的效果比 yolox-small 好一些,遂决定从源码解读一下这是为什么,网上很多解析基本都是翻译论文,没啥价值,还是决定仔细读一下代码。
Model 部分
和其他检测模型一样,model 分为 backbone,neck 和 head。
backbone
backbone 采用 CSPDarkNet,包括 stem,dark2,dark3,dark4 和 dark5。
- 数据经过增强处理并缩放到
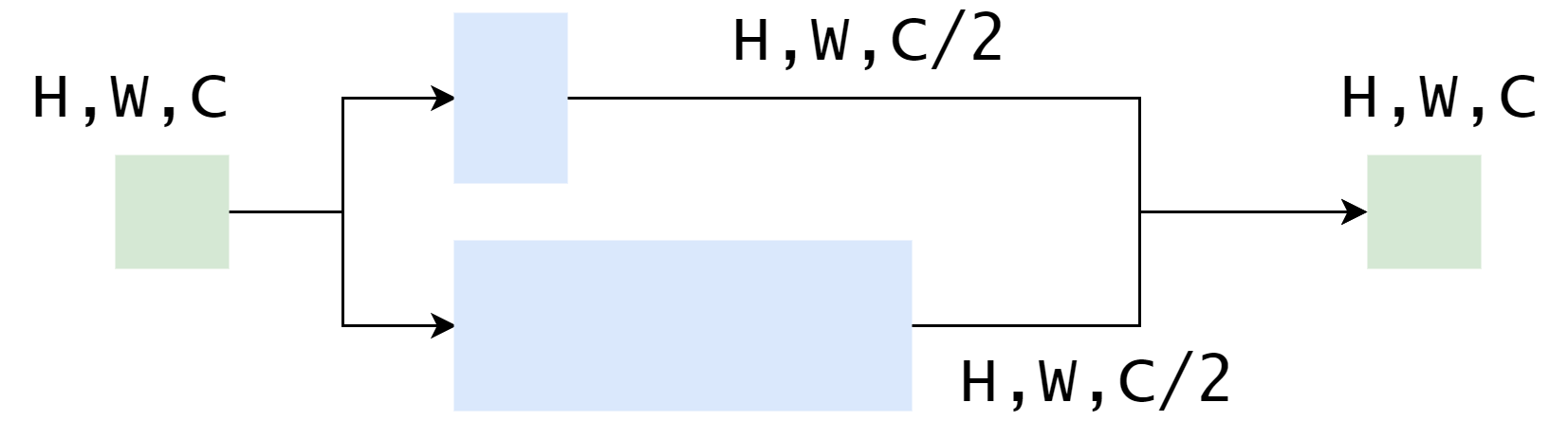
640X640大小后进入stem完成图像通道的升维,从3通道提升到X通道,X取决于backbone规模的width_factor参数。图像经过这一层之前,会被均匀切分为左上、右上、左下和右下四个区域并按通道拼接得到160X160X12的数据,也就是 12 个通道,每个通道的图像大小占据原图像大小的1/4,在经过卷积、BN层和激活层,得到输出。 stem的输出进入dark2,经过一个卷积模块,维度提升一倍后尺寸减半。而后经过CSPLayer,CSPLayer的结构和残差网络相似,一个分支只对输入卷积一次,零一个分支进行深度特征提取,深度的层数取决于backbone的depth_factor参数,而后两个分支的输出按照通道数拼接到一起,完成升维。dark3, dark4, dark5的东西和dark2一致,无非是尺寸减半,通道数翻倍,同理得到dark3, dark4, dark5的输出。
这里补充一下:
dark3的输出维度:256X80X80dark4的输出维度:512X40X30dark5的输出维度:1024X20X20
neck
获取 backbone 的 dark3, dark4, dark5 的输出作为输入。这里描述太复杂了,简单的画图展示一下大概结构,精细的结构还是要看源代码:
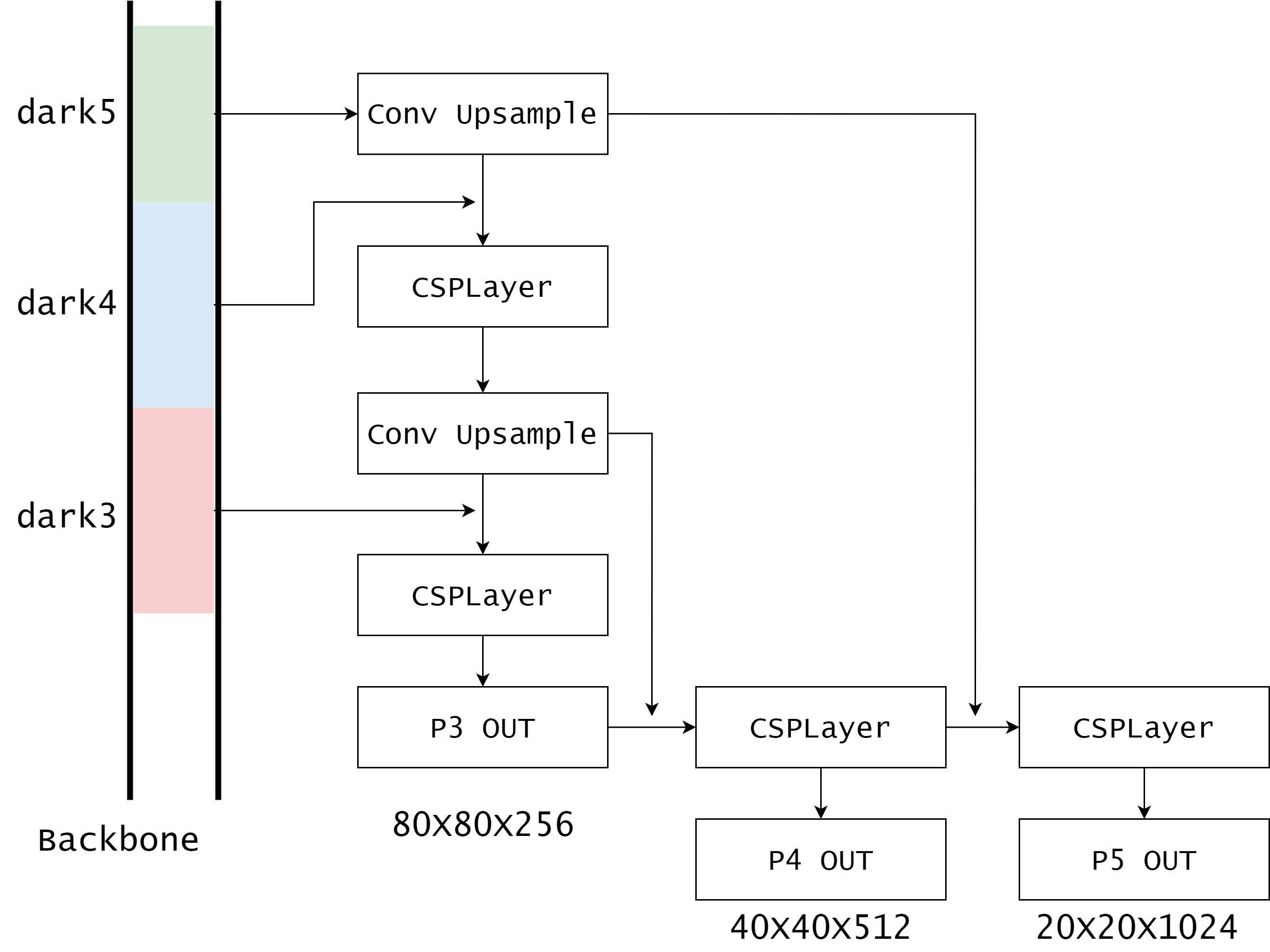
head
因为 neck 有三组输出,所以 head 对 neck 的每一组输出都要进行处理。对每一个输入经过不同的 stem 把通道数降维到 256,而后接入解耦的任务分支,包括分类(cls)、位置框(reg)和前背景(obj)三个网络,分类网络的输出通道数是类别数,这里假设为 2,回归网络的输出通道数是 4,负责预测中心点坐标和高宽尺寸,前背景网络的输出通道数是 1,因此输出的通道数是 2+4+1=7。将这三个网络的输出然后拼接到一起,放到一个列表中。因此,head 部分得到的输出为三组数据:7X80X80, 7X40X40, 7X20X20。以 7X80X80 表示预测了 80X80 个目标,每个目标包括位置、类别和前背景共 7 个参数。
训练部分
这一部分是难点,或者说,是任何目标检测算法的实现难点,代码量也是最大。
预处理
在这一部分,将对 head 的三个输出进行一些转换并生成对应的 grid 信息,将预测输出对应到图像中的实际位置。这一部分大概分以下步骤:
- 获取输出特征的的宽度和高度,如 80 和 80,或者 40 和 40,那么就生成对应的
grid,如 [0, 1] [0, 2] ... [80, 80] 共 6400 个,维度是 [1, 6400, 2] - 将预测结果
reshape成Batch, HxW, C大小,坐标的x和y加上grid会映射到每个预测特征点的中心位置,在乘以 8,也就是理想情况下位置信息的运算结果会在 640 X 640 之间,也就是图像上目标的起始点 - 计算
w和h的 $e$ 次方,再乘以 8,得到目标框的高度和宽度。此时返回得到的grid和变换过后的output。(80 对应的扩张步是 8,40 对应的扩张步是 16,20 对应的扩张步是 32)
将每一个输出经过上面 3 个步骤的处理后,按照 dim=1 拼接到一起,也就是会得到 Batch, 8400, 7 的输出。
损失计算
针对 batch 中的每一个图像开始处理:
- 如果真实标签显示这个图像没有目标,全部真实标签就是清一色的 0,分类个数全部是 0,位置参数是 4 个 0,有无目标是 8400 个 0,
fg_mask全部是false。(fg_mask的用途后面会讲) - 否则,取出这个图像包含的全部真实目标框,与预测结果进行传说中的 SimOTA 样本分配,为预测结果分配标签,或者说为标签分配预测结果,因为 8400 个预测结果不可能同时参与训练
SimOTA
首先计算真实框覆盖的 grid 中心点,将这些 grid 中心点称为 fg_mask 也就是正样本,但是这样选择的正样本会很少。于是还会选额落入真实目标框的周围的预测结果视为正样本,周围的度量方式是:当前特征点乘以 2.5 倍的步长所覆盖的格子,取出同时在真实目标框内和真实目标框周围的预测结果视为 fg_mask,从所有的预测结果中通过 fg_mask 把正样本取出来,包括位置,类别和前背景。
之后计算选中的位置和真实位置的 iou 得分和损失;将类别的输出激活后和 obj 的激活输出相乘得到类别得分,以此得到类别损失;将没有被选中的预测结果视为负样本,计算预测失败的损失,有一个预测结果不在,损失就是1,有 100 个不在,就是 100,然后计算这三个损失的和。
之后进行动态 k 分配,这里的 k 计算比较简单,在 10 和上一步骤选中的 fg_mask 数量取最小值就是 k,给每个真实框选取损失最小的 k 个预测结果。如果当某一个特征点指向多个真实框的时候,选取 cost 最小的真实框,之后对 fg_mask 进行更新。
计算损失
obj损失是全部的预测结果和动态 k 分配后得到的fg_mask做交叉熵cls损失基于fg_mask选中的样本,将类别的one-hot向量与正样本和真实框的 iou 做乘积reg损失是就是预测盒子和真实盒子的 iou 损失
问题解决
如何解释开头的问题以及如何调优呢?通过一路 debug 找到了一些问题,我目前只发现了一点点问题,等我彻底解决完毕回来填坑(因为又又又摸不到显卡了)。
- 第一点,由于是单目标检测任务,也就是说只有一个目标,那么小模型参数少,很容易聚焦和收敛;而大模型参数大,解空间也会更多,相对小模型难以探索到更好的解,因此一些常见的
trick(比如预训练backbone)才会有效的提升大模型的检测效果,而对小模型而言,参数少,搜索空间小,很容易找到更优的解,因此一些trick并不会起到很大的作用。 - 第二点,由于检测任务绝大多数目标是小目标,而 yolox-tiny 模型尺寸小,输出的通道数也少,底层的特征信息的保留程度好于大模型,因为模型越深,对图像细节的保留程度就越低。
- 第三点,也是最重要的一点,由于 YOLOX 选取正样本的机制是:预测结果落入真实框,或者落入真实框的周围,这些落入真实框周围的正样本在模型初期会侥幸存活下来并通过
SimOTA,但是,由于大部分都是小目标,会导致预测结果和真实目标毫不相交的场景,这就reg分支的 IoU Loss 不起作用,我们换成 CIoU Loss 就可以了。
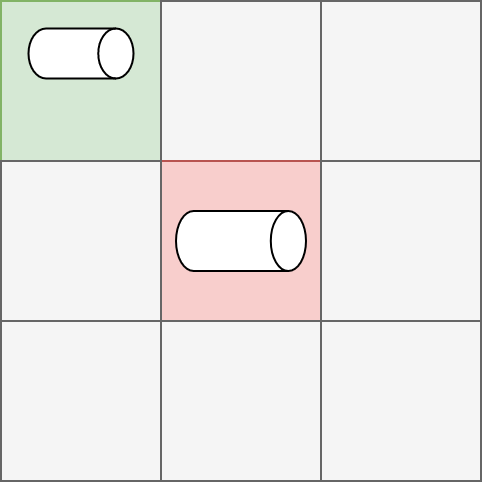
如图所示,红色是真实框,绿色是落入真实框周围的预测结果(正样本),灰色表示不参与训练。可以看到,由于目标较小,预测结果和真实标签毫不相交,IoU Loss 的损失是 0,这显然是不合理的,应该是一个很大的数,而 CIoU Loss 能很好的解决这一点。
如果你要从发论文的角度调优 yolox,那么建议改动它的 SimOTA 机制,但是这也只能是为了毕业而发的一篇普通的论文,还远远达不到 yolov6 问世的高度。如果是工程的角度,那么 CIoU Loss 会很适合你。结果也显示,使用 CIoU Loss 的 mAP 要远远高于不使用和 yolox-tiny,提升 4.1 的 mAP。


评论区